Training Image Estimators without Image Ground-Truth
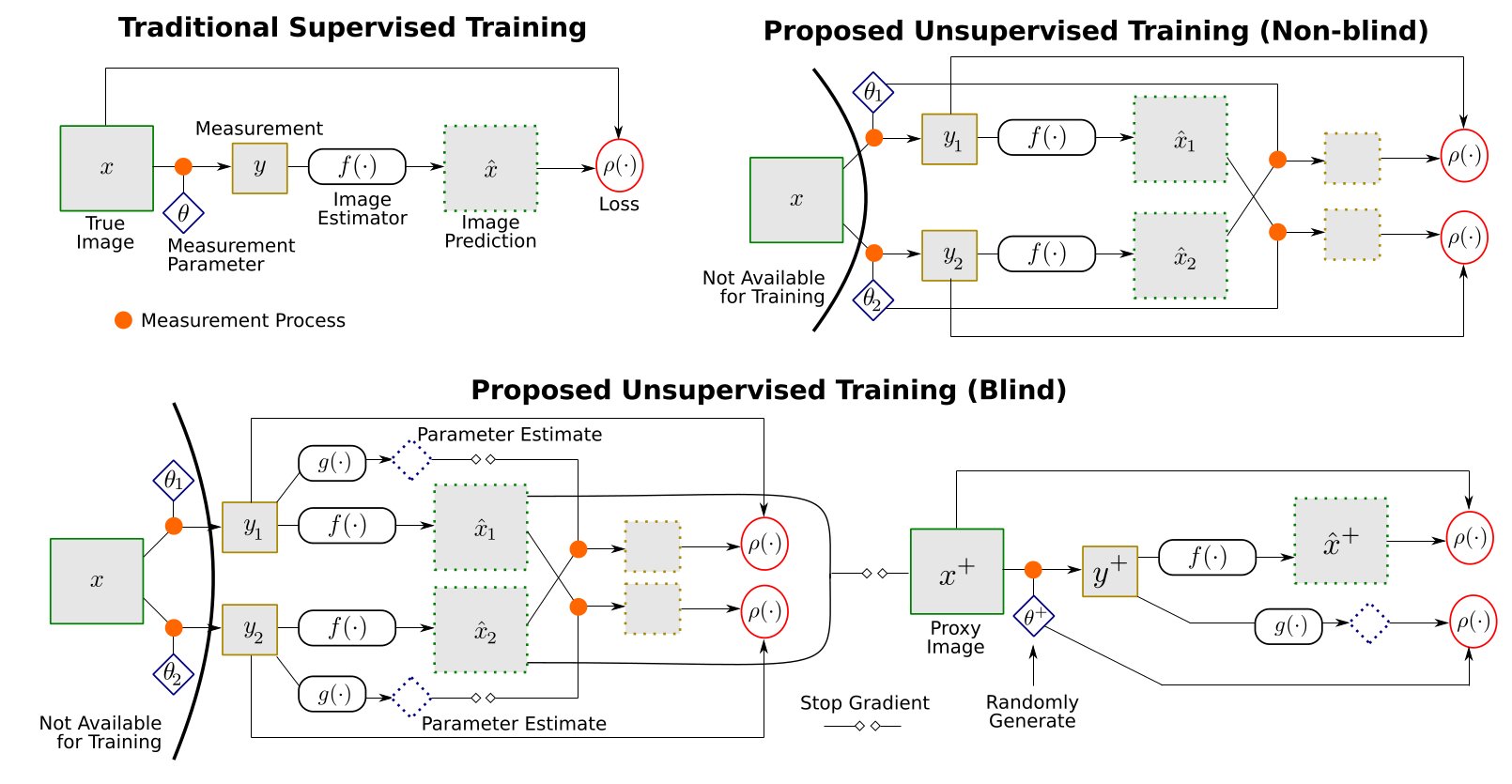
Deep neural networks have been very successful in image estimation applications such as compressive-sensing and image restoration, as a means to estimate images from partial, blurry, or otherwise degraded measurements. These networks are trained on a large number of corresponding pairs of measurements and ground-truth images, and thus implicitly learn to exploit domain-specific image statistics. But unlike measurement data, it is often expensive or impractical to collect a large training set of ground-truth images in many application settings. In this paper, we introduce an unsupervised framework for training image estimation networks, from a training set that contains only measurements---with two varied measurements per image---but no ground-truth for the full images desired as output. We demonstrate that our framework can be applied for both regular and blind image estimation tasks, where in the latter case parameters of the measurement model (e.g., the blur kernel) are unknown: during inference, and potentially, also during training. We evaluate our method for training networks for compressive-sensing and blind deconvolution, considering both non-blind and blind training for the latter. Our unsupervised framework yields models that are nearly as accurate as those from fully supervised training, despite not having access to any ground-truth images.
| [arXiv preprint] | NeurIPS 2019 paper (spotlight) |
| [Source Code] | GitHub repo with code & pre-trained models |
This work was supported by the National Science Foundation under award no. IIS-1820693. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors, and do not necessarily reflect the views of the National Science Foundation.
This site uses Google Analytics for visitor stats, which collects and processes visitor data and sets/reads cookies as described here.