Generating and Exploiting Probabilistic Monocular Depth Estimates
Zhihao Xia Patrick Sullivan Ayan Chakrabarti
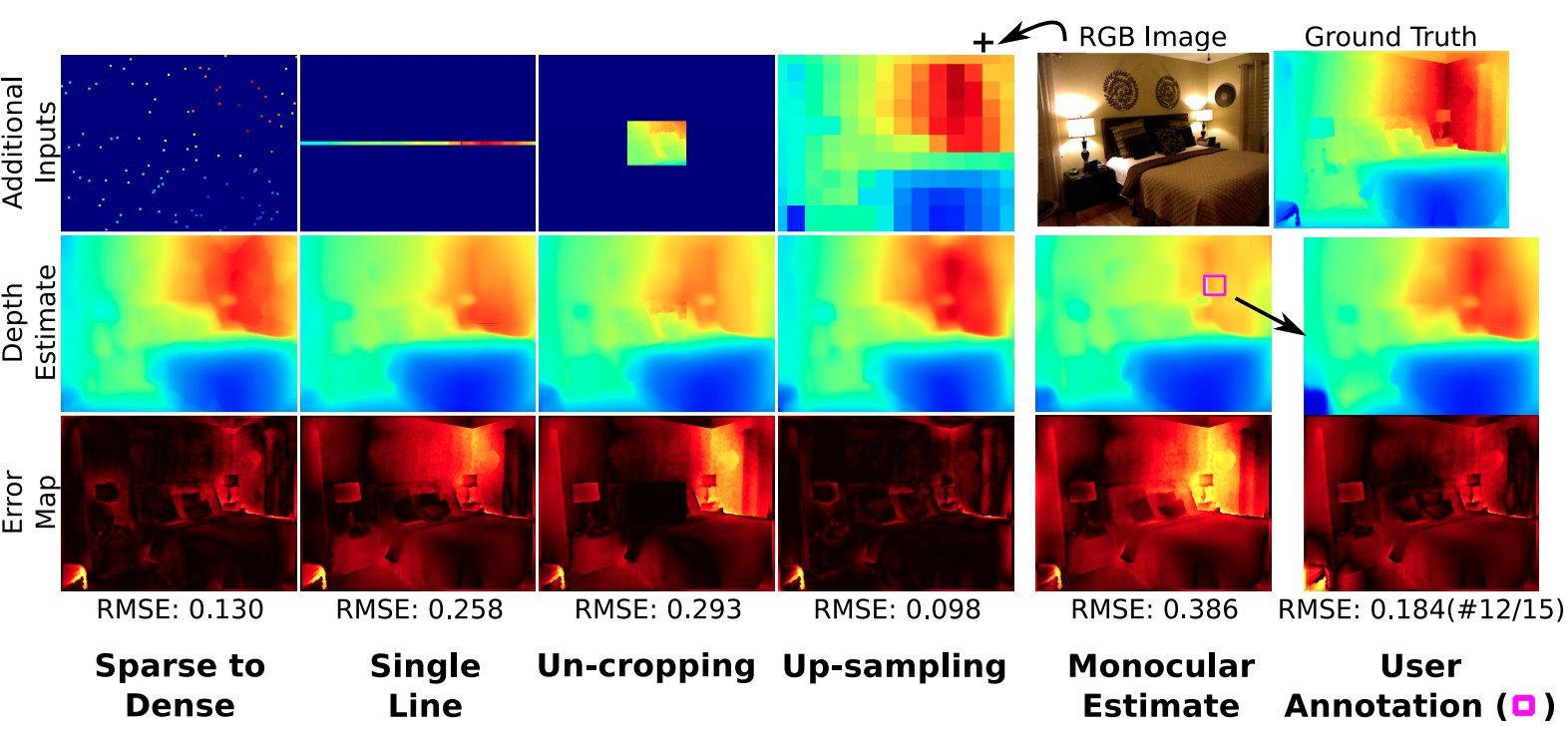
Beyond depth estimation from a single image, the monocular cue is useful in a broader range of depth inference applications and settings---such as when one can leverage other available depth cues for improved accuracy. Currently, different applications, with different inference tasks and combinations of depth cues, are solved via different specialized networks---trained separately for each application. Instead, we propose a versatile task-agnostic monocular model that outputs a probability distribution over scene depth given an input color image, as a sample approximation of outputs from a patch-wise conditional VAE. We show that this distributional output can be used to enable a variety of inference tasks in different settings, without needing to retrain for each application. Across a diverse set of applications (depth completion, user guided estimation, etc.), our common model yields results with high accuracy—comparable to or surpassing that of state-of-the-art methods dependent on application-specific networks.
| [Paper] | CVPR 2020 (oral) |
| [Source Code] | GitHub |
This work was supported by the National Science Foundation under award no. IIS-1820693. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors, and do not necessarily reflect the views of the National Science Foundation.
This site uses Google Analytics for visitor stats, which collects and processes visitor data and sets/reads cookies as described here.